In-memory columnstore databases are all the rage nowadays. But did you know SQL Server already used them back in 2012? The release of SQL Server 2012 introduced columnstore indexes to the SQL Server database engine for the first time ever. Borrowing technology from the Power Pivot engine (now found in Power BI), these indexes drastically improve the performance of large analytical queries – exactly the kind of queries used in data warehouses.
What are columnstore indexes?
Columnstore indexes are indexes which you place on regular tables in a database. Like regular indexes, their purpose is to speed up queries. However, regular B-tree indexes are ideal for finding specific rows in the blink of an eye, while columnstore indexes are optimized for retrieving large volumes of data and aggregating those rows. This means regular indexes are typically used in OLTP scenarios, while columnstore indexes are better suited for OLAP scenarios.
Like regular indexes, columnstore indexes come in two types:
- Non-clustered columnstore indexes: created alongside the table and depending on the query, either the index or the table itself is used to retrieve results. A non-clustered index means your table takes up more storage, since data is duplicated.
- Clustered columnstore indexes: the index is the table. All data is stored inside the columnstore index. Reading data tends to go very fast ̶ changing data, however, not so much.
Columnstore indexes differ from regular indexes in how they are built. As the name suggests, they apply columnar storage. This allows for much better compression of the data. Typically, a 10x compression ratio can be achieved, but this depends to a large extent on the type and distribution of the data. Because the data footprint is much smaller, more data can be read into memory to satisfy queries.
Here’s an example of how using columnstore indexes leads to smaller storage:

Both tables ending in _CCI have a clustered columnstore index. In the data column, you can clearly see their storage footprint is significantly smaller than that of their counterparts (the original tables). A smaller storage footprint means less IO from storage, which means faster queries and more data to fit into memory.
So how does it work?
As mentioned, columnstore indexes store data in a columnar fashion. For each column, only the distinct list of unique values for the entire column is stored. For example, if you have a table with 1,000,000 customers with a column storing for country, a regular table would store 1,000,000 values for the countries. Columnar storage, by contrast, only requires the unique list, which is probably no longer than 200 countries. This is how columnstore indexes can achieve much higher data compression.
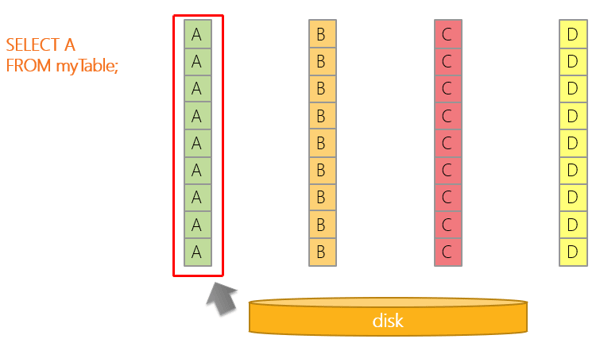
Another advantage of columnar storage is that, in case you only need a couple of columns for a query, you can simply read just those columns. In a regular table, you would have to read all the columns.
Let's illustrate with an easy example. In a regular table, rows are stored as pages. If you need only one column, you still have to read all the rows from the pages.
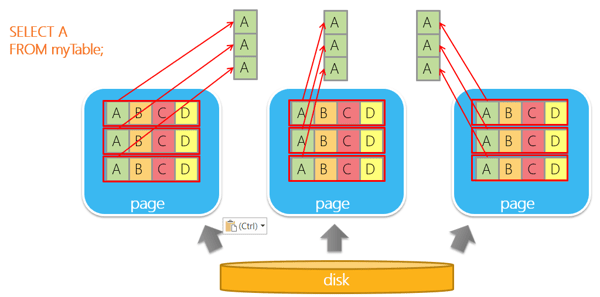
If the data is stored as columns, however, we can just retrieve that specific column. Again, less data to read means faster queries.
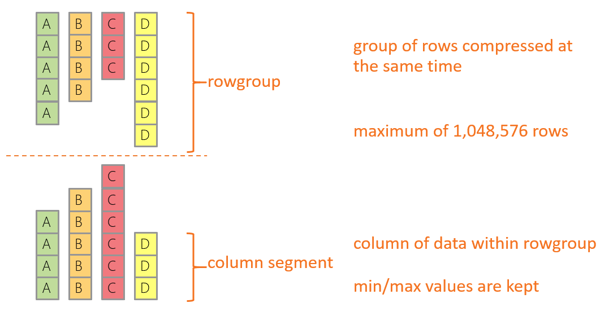
Internally, the data is organized in groups of about one million rows which are then compressed together. Inside each group of rows, only the minimum and maximum value for each column are kept.
When a query filters on a column, the minimum and maximum values can be used to determine whether the entire group of rows can be skipped, which leads to further performance improvements. The screenshot below shows information about a query for which 47 segments have been skipped. Instead of 51 million rows, only 4 million rows have to be read!

A final performance improvement can be achieved by using batch mode. When a query runs in batch mode, the operators in the execution plan will operate on batches of about 1,000 rows instead of on a single row. Needless to say, this speeds up queries tremendously. Keep in mind, though, that not all operators can be run in batch mode and that depending on your query (and the version of SQL Server you have), the query may need to run in row mode.
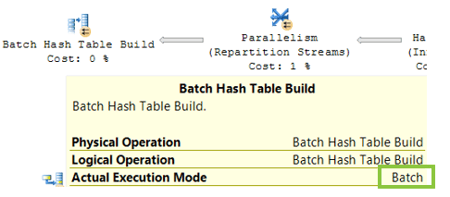
For a query to run in batch mode, at least one columnstore index must be present on the table. However, in SQL Server 2019 it will be possible to use batch mode for regular tables with regular indexes if the optimizer deems it beneficial.
When to use columnstore indexes
Columnstore indexes are ideal for data warehousing. Typically, you don't want to create columnstore indexes in an extremely volatile transactional database, as updating and deleting rows comes at a high cost. Whenever your data is at rest for a longer period of time, columnstore indexes are preferred. Because there is quite some overhead involved, it makes sense to create columnstore indexes only for larger tables with at least a few millions of rows.
Depending on the version of SQL Server, some columnstore index features will not be included or will be available in the Enterprise Edition only.
Here’s an overview of the status quo:
- SQL Server 2012: Only non-clustered columnstore indexes are included (and only in the Enterprise edition), and they cannot be updated. If you want to make any changes, you must drop the index and re-create it. It’s best to use this type of columnstore indexes only if you need to run large reporting queries on large tables.
- SQL Server 2014: Clustered columnstore indexes are introduced. Indexes can now be updated, but there is no unique constraint option available. Also, there’s only one index per table. And again, this feature is Enterprise Edition only. While it is certainly advised to use them in data warehouse scenarios with large tables, you may need to work around some of the limitations.
- SQL Server 2016: you can now mix different types of indexes in one table. B-tree indexes with a clustered columnstore index, an in-memory table with a columnstore index, … What’s more, you can also define unique constraints. Most importantly, though: once SQL Server 2016 service pack 1 has been installed, you can use columnstore indexes in the Standard Edition as well. Just remember that some memory restrictions apply in that case.
A practical example
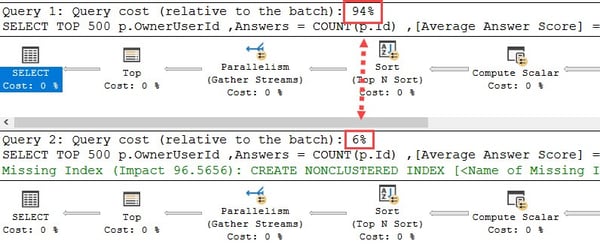
To round things up, let's compare the execution of a single query with and without columnstore index (the query retrieves the top 500 posters on Stack Overflow since August 2016):
SELECT TOP 500
p.OwnerUserId
,Answers = COUNT(p.Id)
,[Average Answer Score] = CAST(AVG(CAST(Score AS FLOAT)) AS NUMERIC(6,2))
FROM dbo.Posts p WITH(INDEX ([NCI_Dummy]))
WHERE p.PostTypeId = 2
AND p.CommunityOwnedDate IS NULL
AND p.ClosedDate IS NULL
AND p.CreationDate >= '2016-08-01'
GROUP BY p.OwnerUserId
HAVING COUNT(p.Id) > 10
ORDER BY [Average Answer Score] DESC;
Without columnstore index, this query runs for about 90 seconds on a table of 33 million rows. With columnstore index, the query only takes about 4 seconds. The execution plan shows the relative costs:
Learn more
Can’t wait to further explore columnstore indexes in SQL Server and improve your skills? Be sure to check out the official documentation as well as Niko Neugebauer’s comprehensive blog post series!
Do you want to be part of our team of data experts? Do not hesitate and contact us via jobs@ae.be or apply your resume here!








